PythonとJupiterを使って音声を分析する【メル周波数ケプストラム】
音声認識をする場合、音声データをそのままの状態で学習させるわけではないことを知りました。どうもメル周波数ケプストラムという状態に変換すると、音から音素データを取り出しやすいとのことです。この技術は各社の音声認識技術において使われているので、試してみました。
メル周波数ケプストラム
もちろん初期状態で使えるわけではありません。
pip install --upgrade sklearn librosa
を実行して、librosaというものをインストールしておきます。
予断ですが、この作業のときに、うっかり「libsora」と入力して、なんでエラーになるんだろうと、かなり悩んでいました。「ロサ」ですよ「ロサ」!!
Pythonのソースコード
ライブラリが優秀なので使うのは簡単です。
import librosa.display %matplotlib inline audio_path = "./data.wav" x, fs = librosa.load(audio_path) librosa.display.waveplot(x, sr=fs, color='blue') mfccs = librosa.feature.mfcc(x, sr=fs) librosa.display.specshow(mfccs, sr=fs, x_axis='time')
Jupiterの実行結果
実際に「あいうえお」という音声を分析してみました。
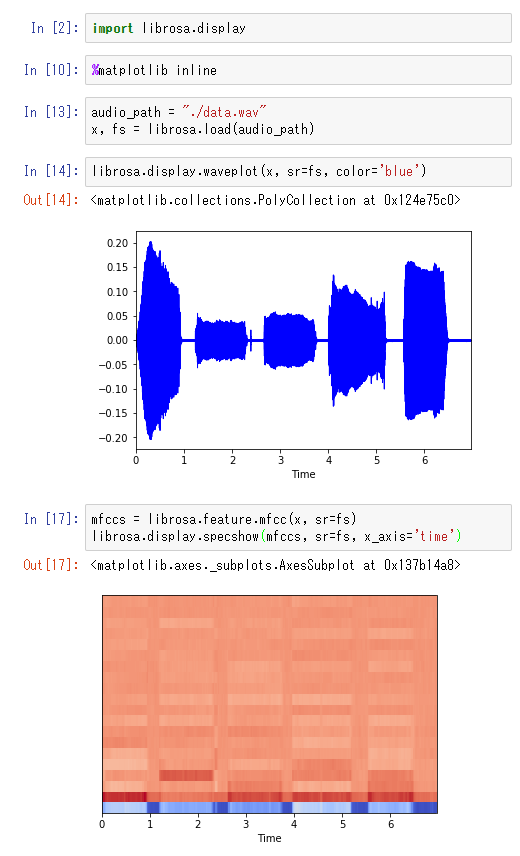
最初のグラフは単純な音量のグラフです。
これから、何の音か分析するのは人間でも厳しいですね。
二つ目がメル周波数ケプトスラムです。
なるほど、確かに音素によって特徴が分かれていますね。
色が濃いところの分布で、音素を特定できそうな気がします。
それでも「う」と「お」は分離が難しいことがわかります。