日本語コーパスを取得する
機械学習を試す上で必要となるのが、日本語コーパスです。
意外とフリーでまとまったデータが無いのですよね。
国会図書館とかNICTが提供してくれると嬉しいのですが。
ライブドアニュースコーパス
https://www.rondhuit.com/download/ldcc-20140209.tar.gz
こちらからダウンロードすることができます。
クリエイティブコモンズなので、技術検証用の学習データにする分には特に権利上の問題は発生しません。
このままでは、記事単位のファイルに分かれていて使うのが面倒です。
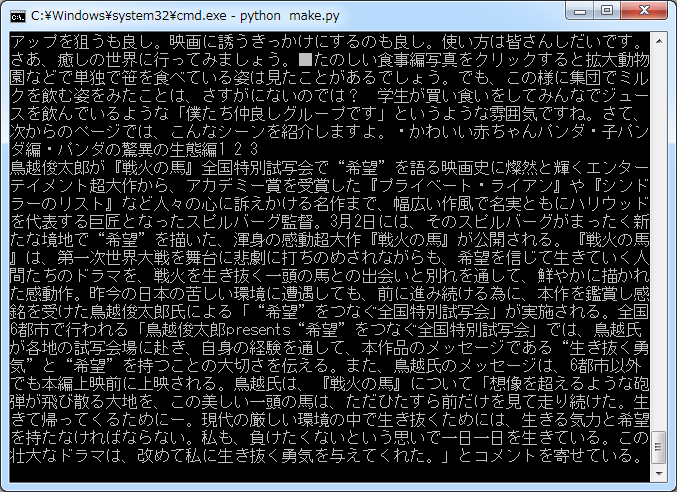
結合させるPythonファイルがいくつかありましたが、どれもWindows環境ではエラーになったので、修正したものを、こちらに記載しておきます。
# coding: utf-8
import os,os.path
import csv
f = open('corpus.csv', 'w', encoding='utf-8')
csv_writer = csv.writer(f,quotechar="'")
files = os.listdir('./')
datas = []
for filename in files:
if os.path.isfile(filename):
continue
category = filename
for file in os.listdir('./'+filename):
path = './'+filename+'/'+file
r = open(path, 'r', encoding='utf-8')
line_a = r.readlines()
text = ''
for line in line_a[2:]:
text += line.strip()
r.close()
datas.append([text,category])
print(text)
csv_writer.writerows(datas)
f.close()インデント関係の不具合と、ファイル入出力時の文字コード指定を追加してあります。たぶん、動くと思うのですが、問題があれば適宜修正してください。
まとめ
およそ25MBくらいのファイルが出力されました。
無料モノなので多くを望んではいけないのでしょうが、記事の品質はイマイチです。