チャットボットに応答機能を実装する
人工知能らしくなってきました。
チャットボットに応答機能を実装します。
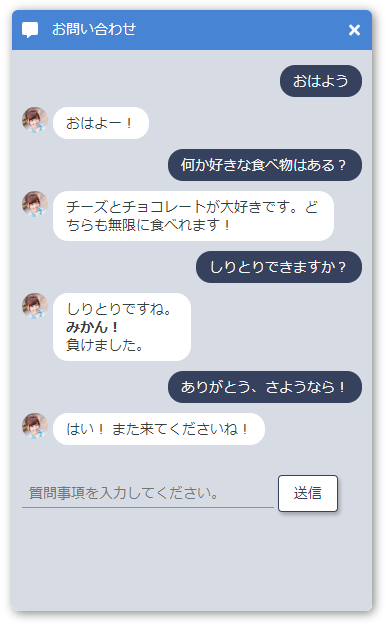
このように、自然な応答ができるようになります。
プログラム
import json
from flask import Flask, request
from gensim.models import word2vec
from scipy import spatial
import sys
import MeCab
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# モデルまでのパス
model_path = 'word2vec.gensim.model'
# モデルの読み込み
model = word2vec.Word2Vec.load(model_path)
mecab = MeCab.Tagger()
# インテント定義
list = []
item = {'intent_id':1, 'sentence':'バイバイ', 'score': 0}
list.append(item)
item = {'intent_id':1, 'sentence':'さようなら', 'score': 0}
list.append(item)
item = {'intent_id':2, 'sentence':'バンコクの食べ物を教えて', 'score': 0}
list.append(item)
item = {'intent_id':3, 'sentence':'好きな食べ物は', 'score': 0}
list.append(item)
item = {'intent_id':5, 'sentence':'しりとりしよう', 'score': 0}
list.append(item)
item = {'intent_id':6, 'sentence':'おはようございます', 'score': 0}
list.append(item)
# レスポンス定義
res_list = []
item = {'intent_id':1, 'response':'はい! また来てくださいね!'}
res_list.append(item)
item = {'intent_id':2, 'response':'ガパオとかあるみたいですね。'}
res_list.append(item)
item = {'intent_id':3, 'response':'チーズとチョコレートが大好きです。どちらも無限に食べれます!'}
res_list.append(item)
item = {'intent_id':5, 'response':'しりとりですね。<br><strong>みかん!</strong><br>負けました。'}
res_list.append(item)
item = {'intent_id':6, 'response':'おはよー!'}
res_list.append(item)
# テキストのベクトルを計算
def get_vector(text):
sum_vec = np.zeros(50)
word_count = 0
node = mecab.parse(text).splitlines()
for item in node:
if item.split('\t')[0]=='EOS':
break
field = item.split('\t')[1].split(',')[0]
# print(item.split('\t')[0] + field)
if field == '名詞' or field == '動詞' or field == '形容詞' or field== '感動詞':
try:
sum_vec += model.wv[item.split('\t')[0]];
except KeyError:
print('KeyError [' + item.split('\t')[0] + ']')
word_count += 1
return sum_vec / word_count
# 文章間の類似度を計算します
def sentence_similarity(sentence_1, sentence_2):
sentence_1_avg_vector = get_vector(sentence_1);
sentence_2_avg_vector = get_vector(sentence_2);
return 1 - spatial.distance.cosine(sentence_1_avg_vector, sentence_2_avg_vector)
app = Flask(__name__)
# エントリポイント
@app.route('/')
def get_request():
input_sentence = request.args.get('text', '')
callback = request.args.get('callback', '')
# 入力語句と例文の類似度を測定する
for item in list:
item['score'] = sentence_similarity(item['sentence'], input_sentence)
if str(item['score']) == 'nan':
item['score'] = 0
# 類似度順にソートします
scores_sorted = sorted(list, key=lambda x:x['score'], reverse=True)
intent_id = scores_sorted[0]['intent_id']
score = scores_sorted[0]['score']
if score < 0.7:
response = '申し訳ありません。<br>よくわかりませんでした。'
else:
for res in res_list:
if res['intent_id'] == intent_id:
response = res['response'];
dic = {'output' : [{'type' : 'text', 'value' : response }] }
# dic = {'output' : [{'type' : 'image', 'value' : 'https://lohas.nicoseiga.jp/thumb/5280206i' }] }
contents = callback + '(' + json.dumps(dic) + ')'
return contents
if __name__ == "__main__":
app.run(debug=True)前回までのプログラムに、類似度判定と応答メッセージの選択処理を追加しました。リストが2つありますが、インテントは「意図」でレスポンスは「応答内容」です。この2つのリストはintent_idで紐付けされています。
類似度判定なので、例文と全く同じ内容を入力しなくても通ります。ある程度は話者の意図を読み取ってくれます。AIっぽいですよね!
現在はインテントとレスポンスをプログラムに直接書いていますが、実用的なシステムにするためには、これらの定義はデータベースなどに持つべきでしょう。そして、メンテナンスする画面も必要です。またはエクセルのファイルを取り込む機能を持たせるなどの発展系も考えられます。
まとめ
商用のチャットボット製品は、あらかじめ応答文例がある程度、組み込まれているのがメリットですね。この例では、他のチャットボットの応答を参考にしました。Microsoftのりんなとか作り込みがすごいです。